
What this blog covers:
- How enterprises can integrate data from multiple sources, maintain the semantics of each source and track historical changes using data vaults
- Capturing human knowledge not reflected in traditional databases through knowledge graphs.
- Uncovering the synergies between the robust infrastructure of data vaults and the context-rich ecosystems of knowledge graphs.
A data vault (DV) is a data modeling approach and methodology for data warehouses that facilitates the integration of data from multiple sources while maintaining the semantics of each source and tracks historical changes. DVs stand out for their semantic richness, offering a more nuanced organization of attributes across entities and domains that preserve lineage and evolution. This depth not only differentiates them from traditional data warehouses but also aligns them more closely with the characteristics of Knowledge Graphs (KGs). Despite appearing as seemingly unrelated concepts, a detailed examination shows that DVs share essential qualities with KGs, such as methodical structuring, historical accuracy and scalability, bridging the gap between structured data storage and the interconnectedness of semantic networks.
The TL;DR is that DVs are closer to KGs than traditional star or snowflake data warehouses. Therefore, they are more amenable to contributing the innate semantics contained within towards the inferential power inherently stored in KGs.
This article ventures into the heart of this relationship, uncovering the synergies between the robust, reliable infrastructure of DVs and the dynamic, context-rich ecosystems of KGs. It posits that the journey from DVs to KGs isn’t merely a leap but a natural progression towards a more integrated, semantically-enriched data paradigm. By weaving together the structured, agile foundation of DVs with intricate KGs built to semantic web standards, we can entertain the concept of what I’m calling a “Knowledge Vault” — a derived product of a DV that promises to bridge these two worlds, melding the reliability and auditability of the former with the semantic richness and interconnectivity of the latter.
This exploration not only highlights the compatibility and potential synergies between DVs and KGs but also sets the stage for a transformative approach to managing and extracting value from data in today’s increasingly complex and dynamic environments.
We’ll begin with very brief overviews of the DV methodology and KGs, then discuss the bridge between them.
The Essence of Data Vault Architecture
Delving deeper into the essence of DV architecture reveals a methodologically sophisticated framework designed not just for the storage of data, but for preserving its integrity, context and lineage over time. This methodology, conceptualized to address the multifaceted challenges of data management in modern enterprises, is distinguished by its foundational components: hubs, links and satellites. Each plays a pivotal role in creating a comprehensive, agile and scalable data environment that adeptly manages the complexity and dynamism of today’s data landscapes.
Hubs: The Pillars of Business Entities
Hubs represent the cornerstone of the DV architecture, serving as the central reference points for core business entities. They embody the key concepts around which data revolves, such as customers, products or employees. By assigning a unique, immutable identifier to each entity, hubs facilitate a stable and consistent way to reference data across the vault. This stability is crucial for maintaining the integrity of data as it grows and evolves, ensuring that even as the details of business entities change over time, their core identity within the database remains unaltered.
Links: Mapping the Mesh of Relationships
Where hubs are the pillars, links are the intricate fibers that connect them, mapping the rich tapestry of relationships that exist between business entities. From the simple, such as the relationship between a customer and their orders, to the complex ones encapsulating many-to-many relationships, links are what transform the DV from a collection of isolated entities into a dynamic, interconnected ecosystem. This explicit modeling of relationships not only mirrors the natural interconnectedness of business operations but also provides a clear, navigable structure for understanding how entities interact within the broader business context.
Satellites: Capturing Change and Context
Satellites orbit around hubs and links, capturing descriptive attributes, historical changes and the context that breathes life into the raw numbers and identifiers. They are the repositories of change, tracking every modification, addition or deletion of data attributes over time. This historical tracking is not merely a record-keeping exercise; it provides a nuanced, temporal dimension to data analysis, allowing for the reconstruction of past states and the understanding of trends and patterns over time. Furthermore, by decoupling the descriptive and temporal aspects of data from the core business entities (hubs) and their relationships (links), satellites ensure that the system remains agile and adaptable to changes in data structure or business requirements, without compromising the integrity of historical data.
The orchestrated interplay between hubs, links and satellites forms the crux of the DV’s strength: a balanced harmony between stability and flexibility, historical depth and forward-looking agility. Its design principles not only ensure historical accuracy and facilitate detailed analytics but also imbue the architecture with an intrinsic ability to adapt to changing business landscapes. The DV methodology, with its meticulous separation of concerns and its emphasis on data integrity and flexibility, stands as a solution for enterprises navigating the complexities of modern data management, ensuring that their data architecture can scale, evolve and thrive over time.
I’ve written previously about DVs in several contexts, in which I explain them in more detail:
Data Vault Acceleration with Smart OLAP™ Technology (kyvosinsights.com)
Embedding a Data Vault in a Data Mesh
Data Vault Methodology paired with Domain Driven Design
Why is Data Vault Important in Expanding an Enterprise’s Field of Vision
As the “data field of vision” widens, with an ever-increasing volume, variety and velocity of information, organizations face the dual challenge of maintaining the integrity of their historical data while ensuring their data architecture remains agile and scalable. The DV methodology emerges as a pivotal solution in this context, accommodating the complexities and dynamism of modern data ecosystems. Here’s why a DV is particularly suited to this expanding data field of vision.
- Scalability and Flexibility – In an era where the quantity and sources of data are relentlessly expanding, DV’s architecture provides a scalable and flexible framework that can grow and evolve with an organization’s data needs. Its modular design—comprising hubs, links and satellites—allows for incremental additions, updates and modifications without disrupting the existing data structure. The architecture can adapt to new data types, sources and business requirements seamlessly.
- Historical Integrity and Auditability – Maintaining a comprehensive and accurate historical record becomes increasingly challenging yet essential for informed decision-making and compliance. The DV methodology excels in preserving the lineage and history of data, enabling detailed audit trails and the ability to reconstruct historical states. This capability is invaluable for organizations that require precise historical data analysis to inform future strategies and ensure regulatory compliance.
- Enhanced Data Governance – The structured nature of DV, with its clear separation of entity identification (hubs), relationships (links) and descriptive attributes (satellites), facilitates robust data governance practices. As data sources proliferate and the volume of data swells, maintaining high data quality and consistent definitions across the organization becomes crucial. DV’s architecture supports these governance efforts by providing a clear framework for managing data assets, ensuring data consistency and enforcing business rules and data standards.
- Enabling Advanced Analytics and Insights – The ability to derive meaningful insights from vast and varied data sets is a competitive differentiator. The readily agile framework of DV lays the groundwork for advanced analytics and data science initiatives involving data from a wider breadth of enterprise domains. Its design supports complex analytical queries across historical and current data, enabling deeper insights and more informed decision-making.
- Readiness for Future Technologies – As the data field of vision expands, so does the potential for new technologies and methodologies to enhance data analysis and utilization. The DV methodology, with its emphasis on adaptability and extensibility, positions organizations to take advantage of deeper data exploration resulting from the deepening capabilities of cutting-edge technologies such as AI and machine learning, big data platforms and cloud computing. Its architecture ensures that data is primed for these innovations, enabling organizations to stay at the forefront of data-driven opportunities.
The importance of DV in accommodating the expanding data field of vision cannot be overstated. Its architectural principles address the challenges of today’s data management landscape and anticipate the needs of tomorrow. The framework enables enterprises to navigate their broadening data field of visions with confidence and strategic insight.
In this light, the DV architecture emerges not just as a methodology for data storage but as a strategic asset for enterprises seeking to harness their data’s full potential. Its inherent design is a testament to the foresight of anticipating the needs of data-driven decision-making, making it an indispensable foundation for those looking to close the gap between their traditional databases architected to strictly support business processes to more semantically rich and interconnected data paradigms, such as KGs, capable of assistance with inferring new knowledge in a complex world.
- Eugene is a Programmer
- Eugene is a Person
- Person has skills
- Programming is a skill
- Programmer is a Role
- Programmer codes Software
- Programmer knows C#
- C# is a Programming Language
Throughout even a single domain such as Human Resources, there could be hundreds or even thousands of such triples that together encode the “knowledge” of HR.
Figure 1 below is a simple example of a KG housing disparate triples of knowledge.
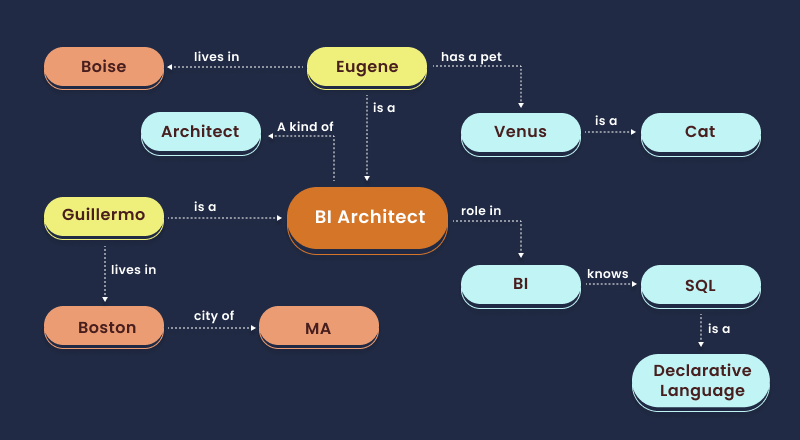
KGs are paramount for several reasons, each underscoring their critical role in advancing how we store, manage and derive value from data:
- Complex Relationship Mapping – KGs excel in depicting complex relationships between diverse entities, offering a multidimensional perspective on data that traditional flat databases simply cannot provide. This ability to map intricate relationships is crucial for understanding the nuanced interdependencies within data, enabling more sophisticated analysis and insight generation.
- Enhanced Data Contextualization – By organizing data in a semantically rich format, KGs provide context to data points, transforming isolated pieces of information into a cohesive, interconnected web of knowledge. This contextualization is key to unlocking deeper insights, as it allows for a more natural exploration of data, akin to how humans understand and relate information.
- Facilitating Advanced Analytics and AI – The structured yet flexible nature of KGs makes them ideal for powering advanced analytics and AI applications, including machine learning models and AI-driven decision-making tools. The semantic richness of KGs provides a solid foundation for these technologies, enabling them to perform more complex, context-aware analyses and predictions.
The Feasibility of Knowledge Graphs Today
The value of KGs has been recognized for decades, but their development and maintenance has been a frustratingly elusive endeavor. However, their growing feasibility can be attributed to several technological and methodological advancements:
- The Emergence of High-Quality and Readily Accessible AI – The level of today’s AI, such as ChatGPT, removes tremendous friction between the communication of knowledge workers accessing databases of many sorts. It is like a very multi-lingual, multi-talented interpreter. What would international communication be without highly linguistic and knowledgeable interpreters?
- Advances in Data Processing and Storage – The exponential growth in computing power and the advent of cloud storage solutions have made it possible to process and store the vast amounts of data required for constructing and maintaining KGs. These technological advancements have lowered the barriers to entry, making KGs a viable option for a wider range of organizations.
- Improved Data Integration Techniques – Modern data integration techniques like data virtualization, data catalogs, metadata management and data fabric have simplified the process of aggregating and harmonizing data from disparate sources. These advancements enable organizations to create KGs that provide a unified view across diverse data landscapes.
Bridging Data Vault and Knowledge Graphs
The journey from data in a DV to KGs is not merely a transformation but an elevation of data’s potential. This path is paved with opportunities to enrich data semantically, making it more accessible and meaningful. Conceptual similarities between DVs and KGs—such as the emphasis on relationships and historical data—lay the groundwork for integration. By adopting semantic web features like Internationalized Resource Identifiers (IRIs) and the Resource Description Framework (RDF), data stored in DVs can be seamlessly transitioned into the semantic, interconnected format of KGs.
The Rise of Semantic Web Technologies
The problem with human knowledge is that none of us thinks or expresses our thoughts exactly the same way. Nor do any of us possess the exact same set of skills and experiences. Some say poh-tay-toh, some say poh-tah-toh. Some think a boot is a kind of footwear, some think it’s a storage space of an automobile. Some rent an apartment, some let a flat.
A KG can become very messy if there isn’t some method for reigning in such variability. That method is the standards of the W3C’s semantic web specifications. Whether we say apartment or flat, we could unambiguously refer to its RDF name, <http://schema.org/Apartment>. The semantic web specifications include:
- Resource Description Framework (RDF) – Specifications for encoding triples of subject-verb-objects.
- Web Ontology Language (OWL) – Specifications extending RDF triples towards building ontologies.
- SPARQL – It is to knowledge graphs that SQL is to relational databases.
- Semantic Web Rule Language (SWRL) – A language for defining rules that can generate more KG elements.
To be clear, the “Semantic Web” isn’t another web alongside what we normally think of as the World Wide Web. It’s a specification to define nouns and verbs unambiguously across all material accessed throughout the Web. We know that a URL defines one and only one web page. Similarly, an RDF resource specifies one noun or verb. It’s just another specification alongside the likes of the more familiar HTTP, TCP/IP, and HTML standards.
The development and standardization of semantic web technologies, such as RDF, SPARQL and OWL, have provided the tools necessary for creating and querying KGs. These technologies facilitate the representation of data in a way that is both machine-readable and semantically meaningful, enhancing the utility and accessibility of KGs.
A particularly intriguing development is the intersection of KGs and AI, the symbiotic relationship KGs share with large language models (LLMs). On one hand, LLMs assist subject matter experts in authoring and refining KGs by providing natural language processing capabilities that can interpret, categorize and link data based on semantic understanding. This collaboration makes the process of building and expanding KGs more efficient and accessible, leveraging the LLMs’ ability to understand and generate human-like text.
On the other hand, KGs serve to ground LLMs in reality, providing a structured, factual basis that LLMs can use to ensure their outputs are accurate, relevant and informed by real-world knowledge. This grounding is crucial for applications where precision and reliability are paramount, such as decision support systems, automated content generation and sophisticated AI assistants.
KGs are the holy grail of analytics. For decades, robust KGs were elusive – much too difficult to build and worse to maintain. But thanks to LLMs, robust KGs are feasible today.
KGs developed within semantic web guidelines offer the richest way to encapsulate knowledge in a fully transparent manner. They represent a paradigm shift in data management, offering the tools and structures necessary to make sense of the vast, complex data landscapes modern organizations navigate. Coupled with the advancements that make them more feasible, KGs stand at the forefront of the next wave of data innovation, promising to transform how we collect, interpret and leverage information.
Semantic Web Features for a Seamless Transition
- The semantic web envisioned as another specification of what we know of as the web empowers data to be shared and reused across application, enterprise and community boundaries. It’s grounded in the principles of making links between datasets understandable not only to humans but also to machines. The transformation from DVs to KGs leverages this visionary framework, utilizing a suite of technologies designed to make data interoperable and semantically rich.
- Internationalized Resource Identifiers (IRIs) serve as the cornerstone of this transformation, providing a universal system for identifying and referencing entities. This global identification mechanism ensures that entities defined within a DV can be seamlessly integrated into the expansive, interconnected network of a KG. The adoption of IRIs transcends traditional boundaries, enabling data to be part of a vast, globally accessible knowledge base.
- Resource Description Framework (RDF) is another pillar of the semantic web, offering a flexible, triple-based structure for representing information. RDF triples—consisting of a subject, predicate and object—mimic the natural structure of sentences, making data representation intuitive and closely aligned with human logic. This model is particularly advantageous for KGs, as it inherently supports the depiction of complex, interrelated data networks. By mapping DV elements to RDF triples, the intricate relationships and attributes stored within DVs are transformed into a format that is not only compatible with KGs but also conducive to semantic querying and analysis.
- Ontologies, within the semantic web framework, offer a structured way to define the types, properties and interrelationships of entities within a domain. They add a crucial layer of context, enabling the formal classification of information and the inference of new knowledge. By incorporating ontologies, the transition from DVs to KGs not only translates raw data into a semantically rich format but also imbues it with a depth of meaning and understanding that facilitates more intelligent data analysis and decision-making.
The Concept of a “Knowledge Vault”
The concept of what I call a knowledge vault (KV) emerges as a link between DVs and KGs. It is a representation of semantics derived from a DV in graph form. It is itself a self-contained KG of what is contained in the vast DV. But with its adherence to semantic web standards, it can readily link to other KGs, in particular, a wider-scoped “Enterprise Knowledge Graph”, which contains knowledge across the enterprise.
A KV is intended as a product derived from a DV. Examples of established products derived from a DV include:
- “Business Vault” (something more akin to a traditional data mart or warehouse).
- “Point in Time” tables (a table of the state of data at some given point in time).
Following are recent articles I’ve written that serve as examples of other graphs that could be sub-structures of a general KG:
Figure 2 below illustrates how a KV is derived from the DV and common objects link it to the Enterprise Knowledge Graph.
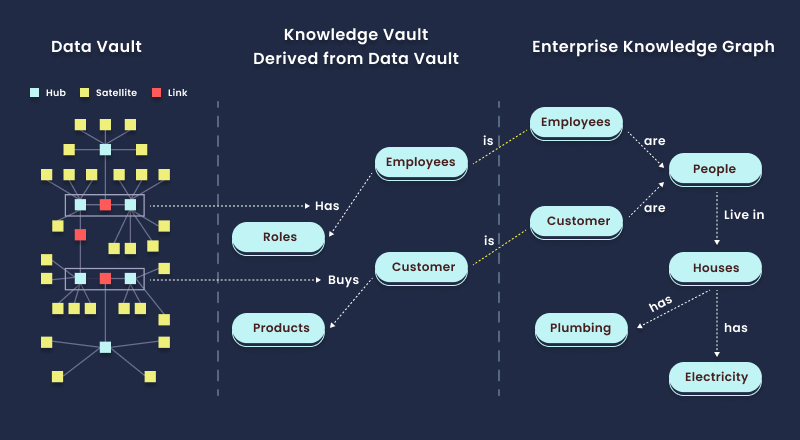
The KV concept transcends the limitations of traditional data architectures, proposing a model where data is not only stored and managed with unparalleled integrity and flexibility but is also enriched with semantic understanding and connectedness. This dual focus on structured integrity and semantic richness opens new avenues for insight generation, decision support and AI-driven applications, positioning KVs as the nexus of future data ecosystems.
Implementation Strategies
Implementing the derivation of data from DVs to a KV entails a strategic mapping of DV components to KG structures, a process that requires both precision and innovation.
From the DV, with its rich structure, a descriptive, enterprise-wide ontology can be derived as part of a KG, which I described earlier as a web of subject-verb-object triples:
- Hubs are the nouns of a DV. For a KG, hubs hold the subjects and objects.
- Satellites store the attributes of those subjects and objects housed in hubs. For example, a customer has a birthdate zip code, and category. Some customers, those from a CRM system but not a sales system, could have a primary support contact person.
- Link tables represent the verb of a DV. So, the name of the link table can stand in for the verb of a triple. For example, a SalesItem link table linking to a product hub and a customer hub would be interpreted as “SalesItem has a product” and “SalesItem has a customer”.
Additionally, an IRI column should be added to all hub tables. IRIs are then assigned to each hub member, ensuring each core business object is universally identifiable and seamlessly integrated into the KG.
Fortunately, the highly methodical nature of DVs and the urgency from Dan Lindstedt—the founder of DV—to strictly adhere to the methodology sets the basis for the feasible derivation of a KV from a DV. That’s because if a methodology is strictly adhered to, it can be automated. Indeed, DVs are generally managed through sophisticated tools such as WhereScape and dbtVault. These metadata-driven tools are used to model the data vault, generate ETL code and other artifacts, and deploy them.
So, the semantic relationships could be encoded as part of the DV tool metadata. At best, the vendors of these tools could add a field for each defined DV column such as “Semantic_Web_Metadata”. At worst, OWL code could be inserted into a freeform field such as “Description”, “Comments”, or “Annotations”. In that latter case, it’s not difficult to programmatically “sniff” out the OWL segments within a larger and general description or comment.
As an example, consider a piece of metadata describing a DV column for a customers’ birthdate. For the description field might enter something like “Customer date of birth”. We could enhance that description by adding an OWL snippet that specifies that in a standardized, semantic way:
@prefix schema: <http://schema.org/>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<http://example.org/customer/12345>
a schema:Person;
schema:birthDate “1964-03-19″^^xsd:date.
Although that OWL snippet may not look pleasing to our human eyes, it’s unambiguous to all KGs out in the world that abide by semantic standards.
Facilitating these transformations demands the introduction to an IT department of tools and technologies that would be somewhat novel. For example:
- Graph databases such as Neo4j, GraphDB and Stardog arise as key players, offering the necessary infrastructure for storing and managing KGs. Their native support for graph structures and semantic queries makes them ideal for hosting complex networks of entities and relationships that define KGs. Alternatively.
- RDF stores such as GraphDB and Stardog provide a specialized repository for RDF data, ensuring that the semantic relationships and attributes are efficiently stored, indexed and queried. Data integration platforms play a crucial role in aggregating and harmonizing data from diverse sources, smoothing the path for its incorporation into the KG.
- Knowledge Graph development UIs such as Protege and Grafo. These are the tools used by subject matter experts to build KGs from ontologies and taxonomies. Think of it as Microsoft Word for building KGs, but instead of encoding knowledge in a spoken language, we encode knowledge with nodes and relationships.
Together, these tools and technologies not only enable the practical realization of KVs but also play a part in the dawn of a new era in data management—one that embraces the structured depth of DVs and the semantic interconnectedness of KGs to unlock a world of possibilities.
Conclusion
In the evolving landscape of data management, the transformation of data from DV to KGs and the conceptualization of KVs represent a practical step forward. This shift is not about discarding traditional methods but enhancing them with the semantic capabilities and interconnectedness that modern data demands. KVs embody a blend of DV’s reliability and the depth of KGs, offering a solid framework for organizations to navigate and make sense of complex data.
The move towards the inclusion of DV data into enterprise knowledge graphs is driven by advancements in semantic web technologies, which enable a more nuanced representation and querying of data. Tools like graph databases and RDF stores are not just facilitating this transition; they’re making it accessible to a broader range of organizations. As we implement KVs, the focus is on leveraging existing data structures in a way that’s both innovative and grounded in practicality.
In essence, the journey to KVs is about preparing for the future of data management in a way that is scalable, manageable and, most importantly, actionable. It’s a step towards making data not just more connected but also more useful, providing a clear path for organizations looking to harness the full potential of their data assets. As we continue to navigate this shift, the goal remains straightforward: to create a data ecosystem as intelligent as it is integrated and ready for the challenges and opportunities of the digital age.