
What this blog covers:
- Continuing the two-blog series on NLP for OLAP Semantic Layers, this part talks about the BI NLP interface with Azure Cognitive Services.
- Discusses the slice and dice questions with sample data used for demonstrating this approach
- Finally, learn how to run an Azure Conversational Language Model and see the demo to understand better
BI NLP Interface using Azure Cognitive Services
A BI NLP Interface – Take 3 – Azure Cognitive Services Approach
This two-part series is about seeking a query method looser than that of rigid visualization tools and SQL. In Part 1, I described how a ChatGPT-centric system is too loose. Interaction with such an A.I. is prone to inconsistency from query to query. Meaning, it might answer questions differently based on what else it has learned from interactions, tweaks to its algorithm and training data, and just some built-in randomness.
For querying business data, I opt for greater control of building the system using Azure Cognitive Services components. Instead of “the big A.I.” approach, we’ll take a step or two back towards the less grandiose notion of “applied machine learning”. With the Azure Cognitive Services components, we have more control over how and when models are trained.
This approach offers a safer middle ground. Each Azure component has a limited scope and is secured via Azure’s robust security features. The rest of this article is an abbreviated demo of the sample NLP for OLAP solution I developed. Code, installation instructions, and a tutorial are in a github repository, samples/OLAP_NLP at main · Kyvos-KyPy/samples (github.com).
For the sake of brevity here, I’m skipping over the parts on how to install Python and Anaconda, creating the required Azure resources, setting up the ODBC driver and DSN to the BI data, etc. and glossing over tutorial-level details. This is a list of the high-level tutorial steps:
- Create an Azure Cognitive Services resource.
- Create an Azure Language Services resource.
- Install Anaconda on your laptop.
- Download the code from the github page and install it into your Anaconda base directory.
- Fill in the environmental values in the .env file.
- Create a data source metadata schema file.
- Create the Azure Language Services model for your BI data source.
- Import, train, and deploy your model.
- Run the demo.
Figure 4 below is a sequence diagram for the NLP for OLAP sample solution.
Note: References to Figures 1-3 are in Part 1.
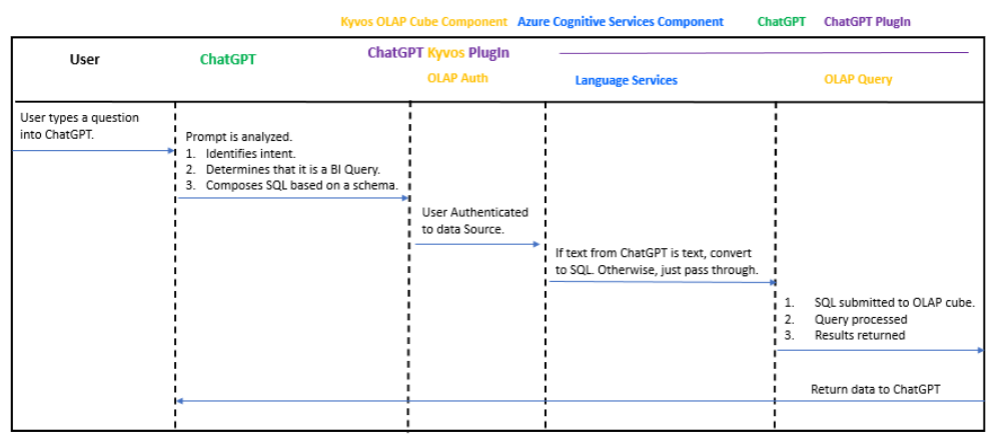
Figure 4 – A query system centered around Azure Cognitive Services.
The Azure Cognitive Services components include:
- Speaker Recognition – In part to ensure the question spoken is from an appropriate person.
- Speech to Text – Capture what was said, recognize the language, and convert it into text. I actually don’t include this service, but it does remove the friction associated with people speaking other languages.
- Speech Translation – Converts the text into English as a common denominator (to avoid a language model per language).
- Language Service – The primary component. It recognizes the intent of the query and identifies entities.
- Text to Speech – Translate a response message into something played back to the user over the laptop speakers.
ChatGPT is optionally involved, but it’s relegated to an auxiliary service. In this role, ChatGPT is like just another person “in the room” adding some “color commentary”. It doesn’t drive the process, nor is it directly privy to any private enterprise information.
Now, this doesn’t mean that an A.I. such as ChatGPT couldn’t infer the schema or sensitive values based on questions it’s asked. That’s the danger of a powerful A.I. For this application at this time, I’d rather keep that widespread and precocious A.I. that learns from human responses out of the mix.
Slice and Dice Questions
The primary class of question we ask of a BI OLAP cube is in the form of slicing and dicing. For example, “What are my sales for whiskey in 2017 by county?” This form of question in a business context is so prevalent that it’s the basis for the GROUP BY clause of a SQL query – as we saw back in Figures 2b-d.
In the settings of a large enterprise, this class of questions involves the aggregation (usually summing or counting) of tens of millions to hundreds of billions of detail-level “facts”. For example, sales line items, web site visit clicks, patient visit events.
The billions of facts could be sliced and diced by any combination of dimensional attributes. There are an uncountable number of queries, but they primarily fall into the slice and dice pattern. A couple other examples of slice and dice queries would be:
- How many bottles of expensive, imported Vodka did we sell during the winter months?
- What is the monthly cost of non-Vodka items in Adams County from 2016 through 2017?
Additionally, beyond the core slice and dice questions, there are other questions (intents) we might ask of a BI OLAP cube. Here are a few examples:
- Metadata: What are the measures and calculations available? What members belong to the dimension representing a “person” type of entity?
- Drill-up/Drill-down: Drill-down from USA to display the values for each state. Or drill-up from the state of California to display the total value for the parent.
- Drillthrough: What are the raw sales orders comprising the total sales the Boise store during March 2017?
I’ve incorporated those classes of questions into an Azure Conservational Language model. The Language model takes these steps:
- Recognizes the intent of the query. For example, slice and dice or metadata request.
- Identifies the entities in the query.
- Returns the intents and entities it determined, along with confidence levels.
The Sample Data
The sample data for this demo is based on data from Kaggle’s Iowa Liquor Sales dataset. I built this dataset into an OLAP cube on the Kyvos platform.
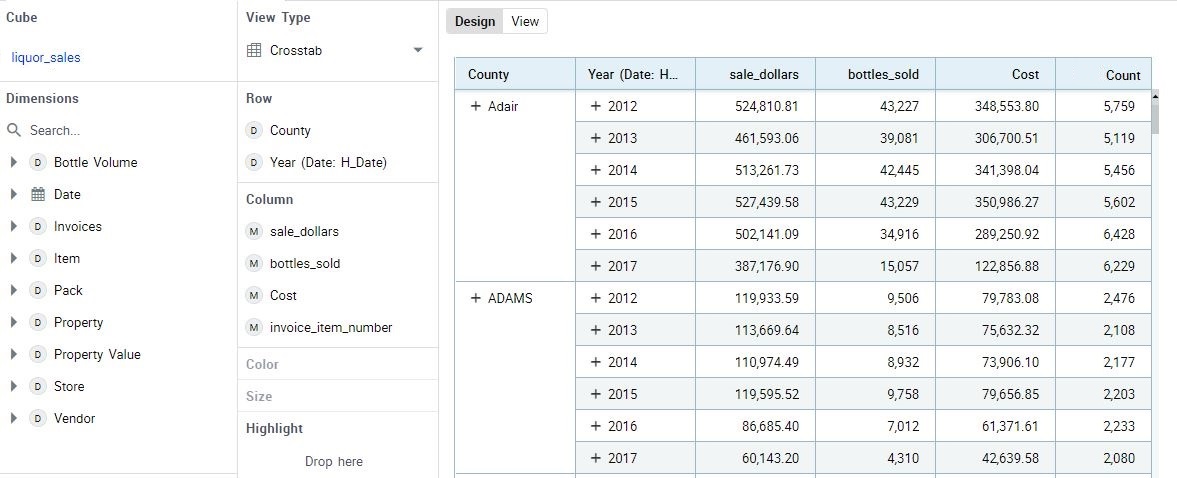
Figure 5 – Sample of a visualization from the sample OLAP cube.
The metadata for this sample cube can be found in the github folder mentioned above.
Creating the Azure Conversational Language Model
The core component of the solution is a language model built on Azure Language Services. To build this model – or a model on any OLAP cube – I’ve developed a Python class named GenCubeLangService. It accepts a json schema document, that could be automatically generated through metadata magic or handwritten, and outputs another json used to configure an Azure Conversational Language Understanding model.
Figure 6 below shows the first few lines of the code for the GenCubeLangService class.
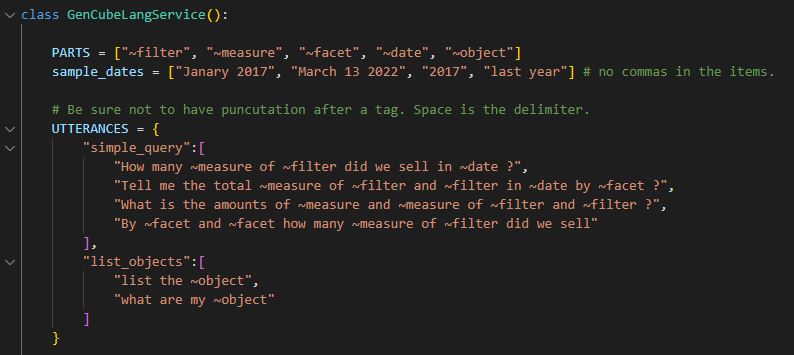
Figure 6 – First few lines of the python class to generate Azure Language Services json.
Notice the json for the variable named UTTERANCES. The “simple_query” and “list_objects” elements represent the core Language Services concept of “intents”. The Language Services model must first recognize the gist of what we are asking. The intent of simple_query refers to slice and dice queries discussed earlier. The array of values for simple_query are a few sample “utterances” (examples of how a simple_query might look) that will be used to train the Azure Language Services model.
Figure 7 is the json document I mentioned a couple of paragraphs ago. It is the input to the GenCubeLangService class providing the metadata about your BI data source. We’ve seen this file before back in Figure 2a, the schema I used to train ChatGPT.
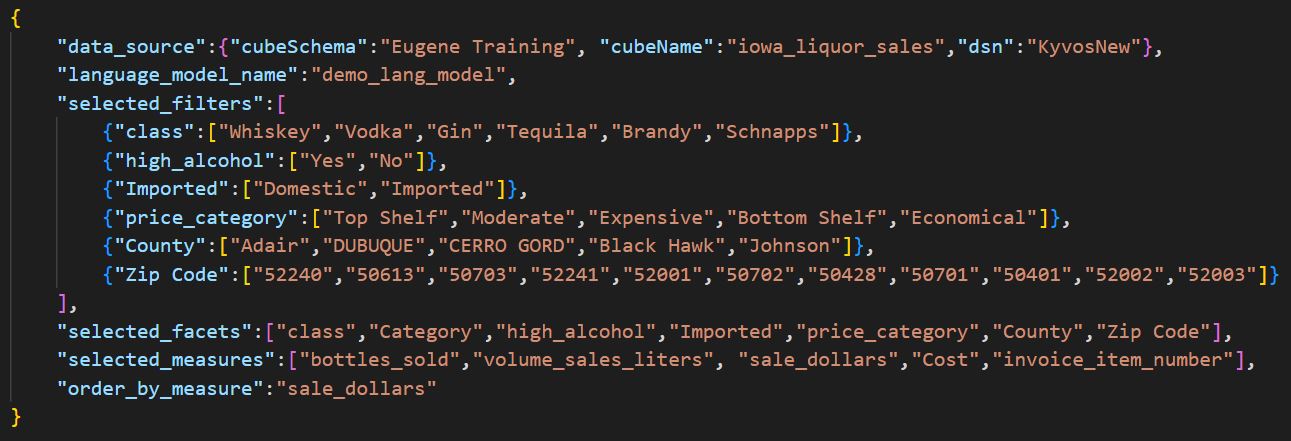
Figure 7 – Metadata and schema for the Azure Language Services model.
The toy example is very simple compared to what would be required of a real-world BI data source. But as mentioned, the metadata json can be automatically generated with relatively straight-forward code. The tutorial on the github page covers this more, as well as more discussion on the definition of things like “facets” and “filters”. For now, it’s enough to recognize that the elements in the metadata file are mostly attributes and members of a BI data source.
With the metadata file in Figure 7, we can generate the json for an Azure Language Services model using the GenCubeLangService class as shown in Figure 8 below.
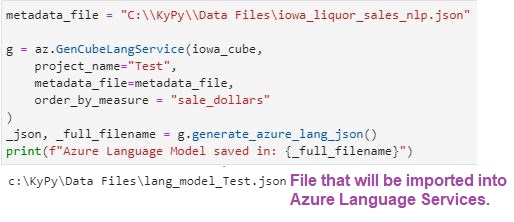
Figure 8 – Simple Python code to Generate the json for our Azure Language Services Model.
That json will be imported into Azure Language Services using Language Studio as shown in Figure 9 below.
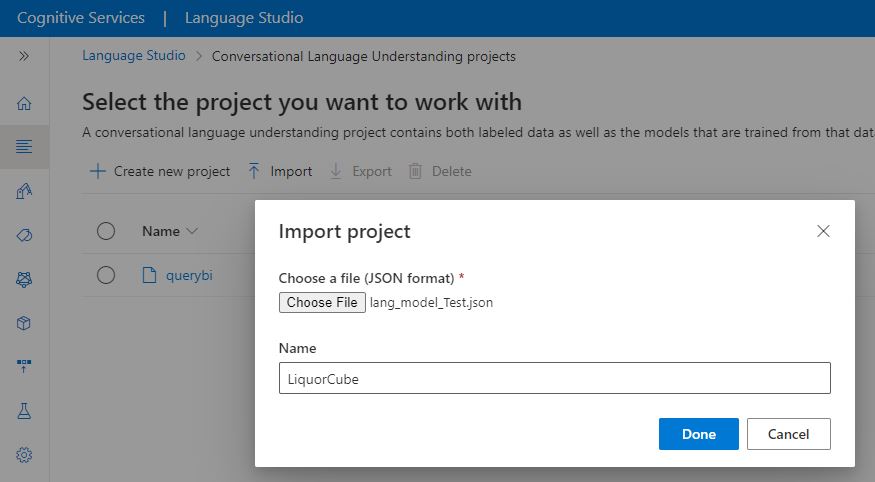
Figure 9 – Import the OLAP cube json as an Azure Language Services model.
After clicking Done, the Language model is created, and let’s examine a couple parts of the model. Figure 10 lists some of the intents prescribed by the GenCubeLangService class. Besides simple_query, there is, for example, intents to list the measures of the BI data source and return the “top n values” of a query.
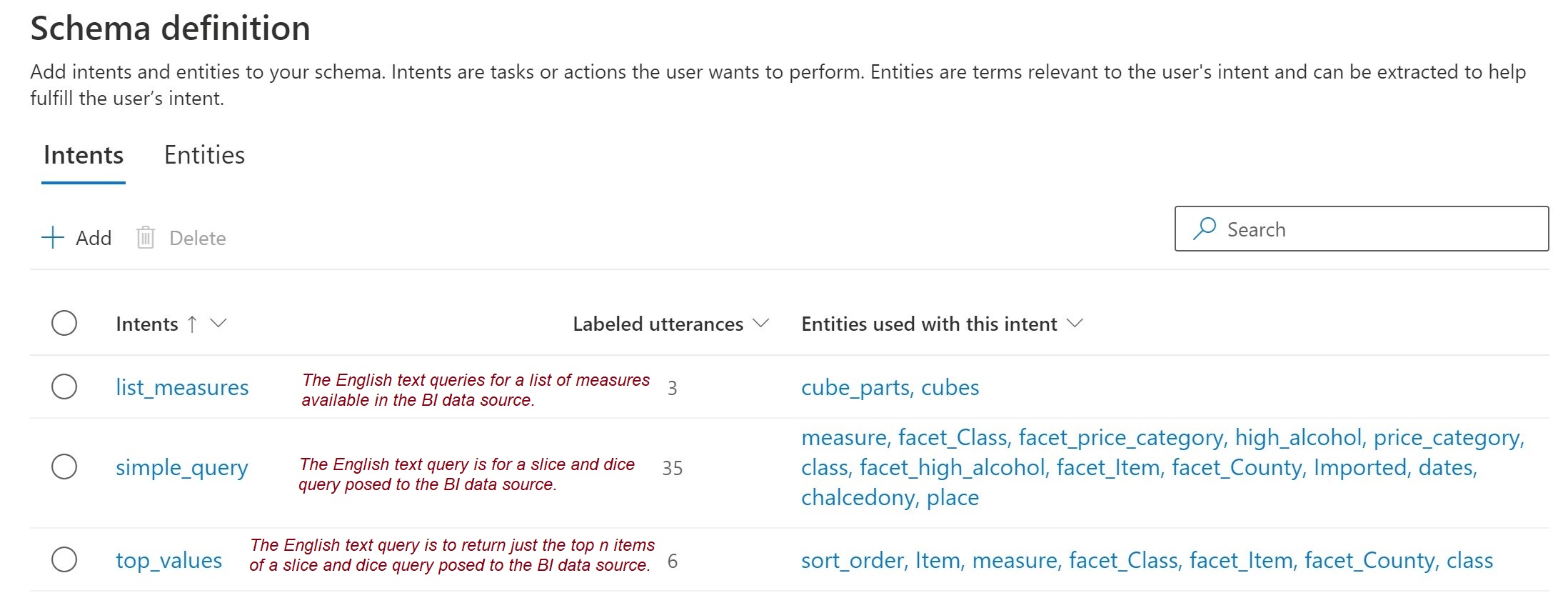
Figure 10 – Intents for an OLAP cube.
Figure 11 shows some of the entities that can be recognized by a spoken language query.
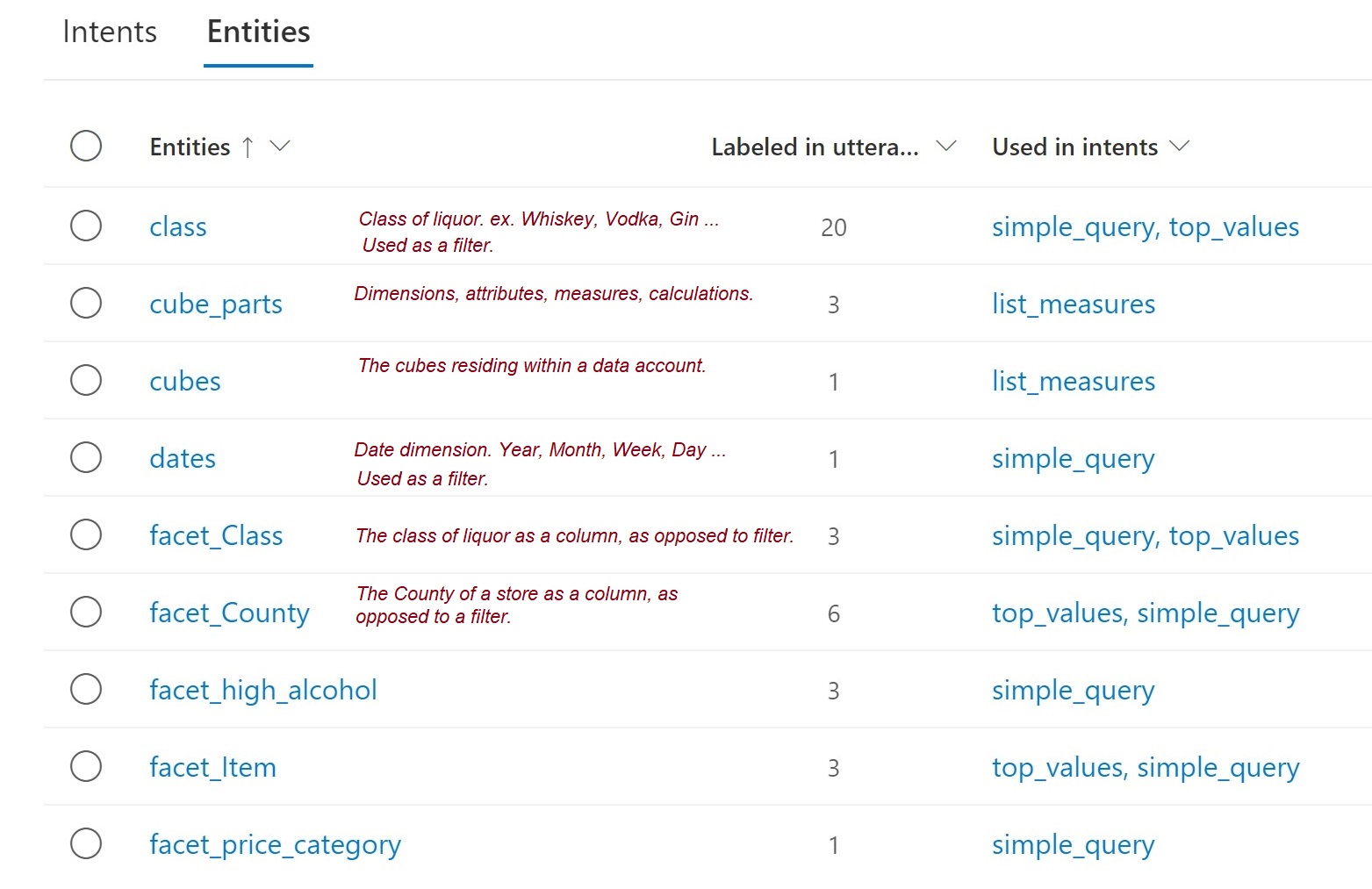
Figure 11 – Entities that could be mentioned within an intent.
We’ll gloss over the steps of training and deploying the model.
Next, we can test if our model recognizes the “intent” of a question. Figure 12 shows how to ask our deployed model (named test) the question we’ve been using throughout this article.

Figure 12 – Test the Language Services model after training and deployment.
Figure 13 shows the results of the test. As you can see, it recognized the “top intent” (most likely meaning) as simple_query as well as identified entities within the query.
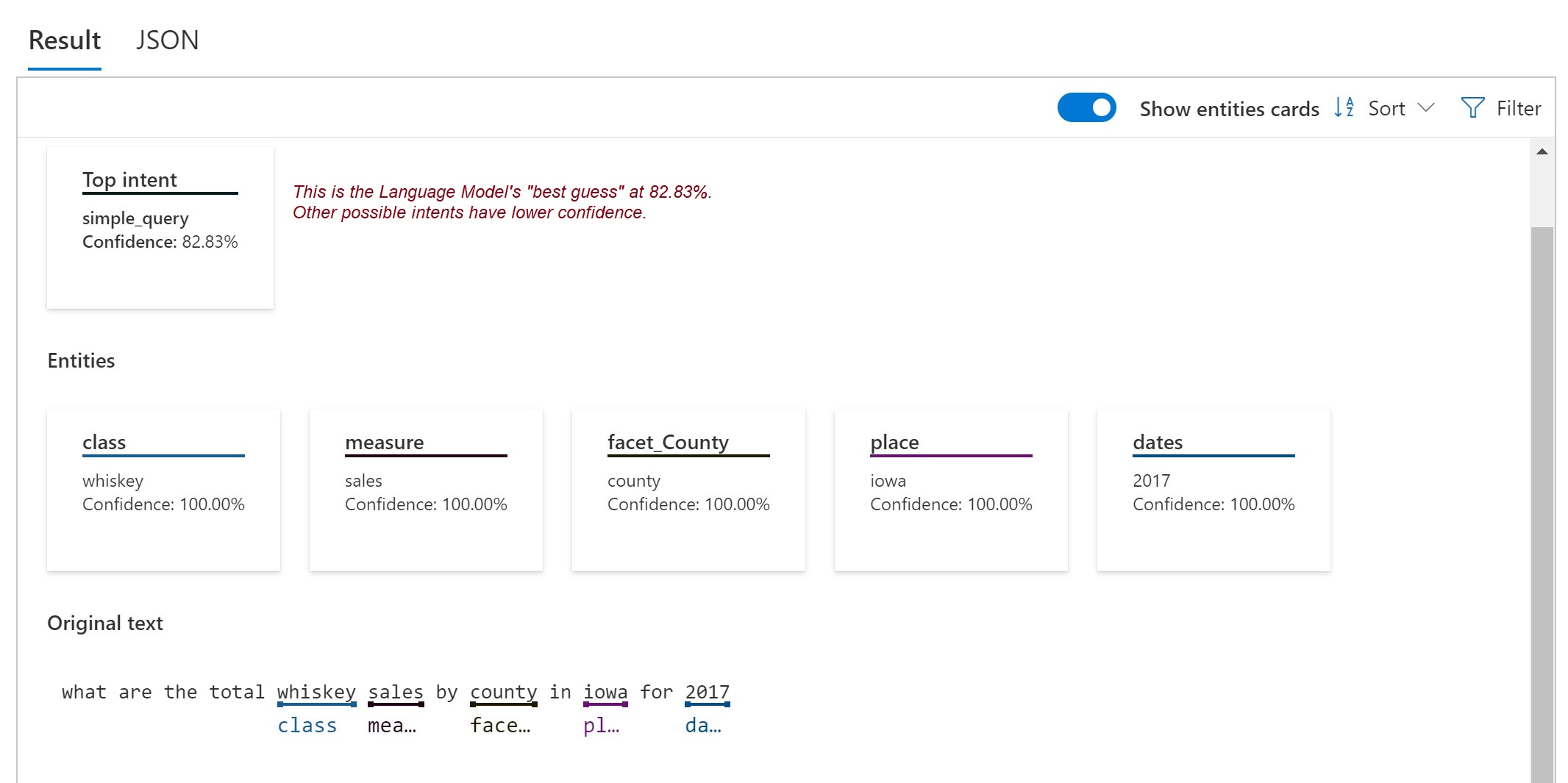
Figure 13 – The results of the test question.
Looking back at the utterance template back in Figure 6, our human brains can tell that the sample utterances at least somewhat resemble the test question in Figure 12. But it’s definitely not an exact fill-in-the-blanks form of any of those samples requiring unforgivingly rigid syntax traditionally required by a computer.
Figure 14a shows the computer-consumable json version of the results graphically shown above in Figure 13. This json is what our NLP for OLAP solution will consume from the Azure Language Services model.
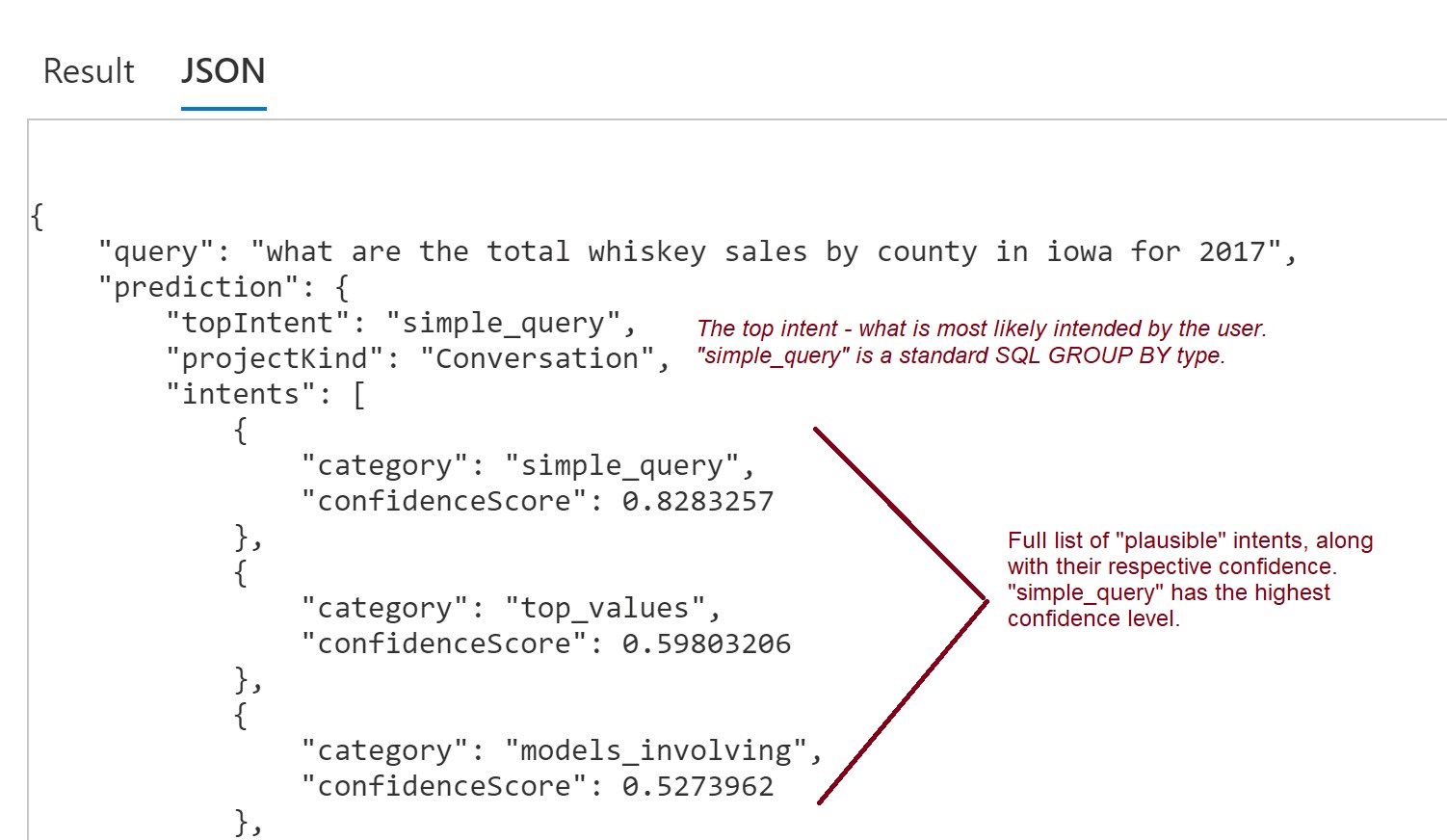
Figure 14a – The json version of the results shown in Figure 13.
Note that simple_query is the top intent with confidence of about 83%. The json also included other possibilities such as top_values (at about 60%). top_values is a possibility since the question would be somewhat similar except it asks for a little more computing (sorting in descending order and returning a specified number).
Figure 14b shows the json of the first few entities that are recognized.

Figure 14b – The recognized entities from the computer-friendly json.
Running the Demo
The demo code requires access to the Azure Language Services resource hosting the model we just created. Granting access is a matter of filling in the first five items of the .env configuration file shown in Figure 15.
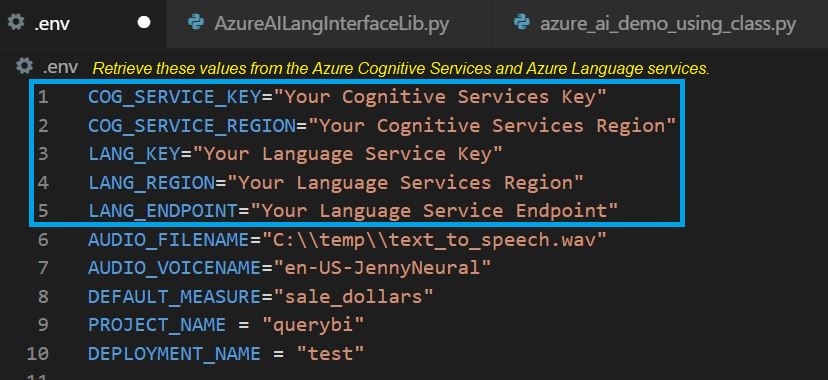
Figure 15 – Environment variables held in a .env file.
The first five lines are values obtained from the Azure Portal for the Azure Cognitive Services and Azure Language Services resources required for this demo.
Figure 16 shows executing the demo with a python script we’ll use to prompt our query and receive results. All of the code is encapsulated in a python class named Language in the AzureAILangInterfaceLib.py file.
Figure 16 – Running the demo.
Figure 17 shows the dialog between the program and me.
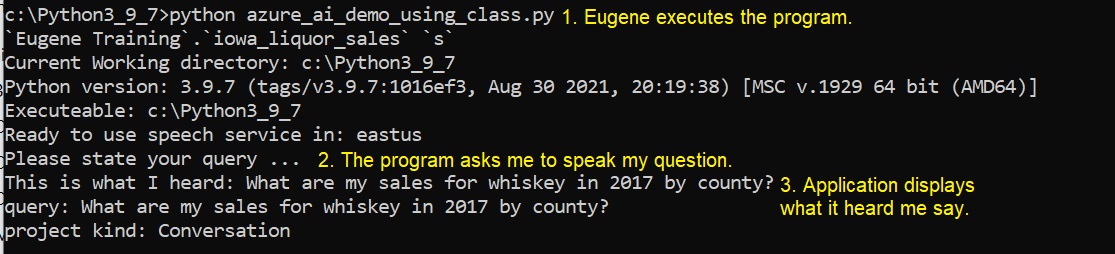
Figure 17 – Presenting our query.
For this demo, I spoke my query into my laptop microphone. I could have instead typed in my query, but I chose to use the speech-to-text functionality.
The query text is submitted to the Azure Language Services model for recognizing an intent and parsing out entities it recognizes. The result of this processing is shown in Figure 18.
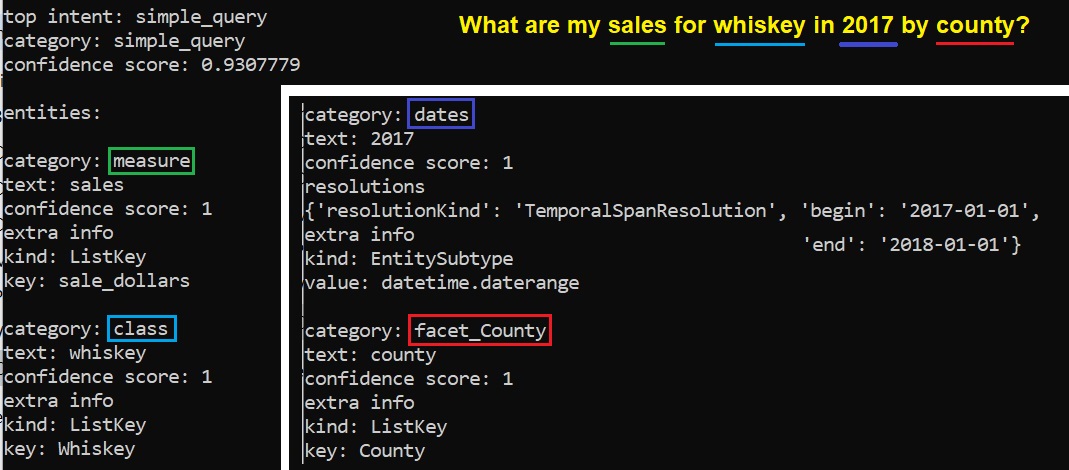
Figure 18 – The interaction of our NLP for OLAP app and the Azure Language Services model.
The python code in the Language class will take those results from the Azure Language Services model (in the form of a json as shown in Figure 14), construct a SQL, and submit it to your data source. That process is shown in Figure 19 below.
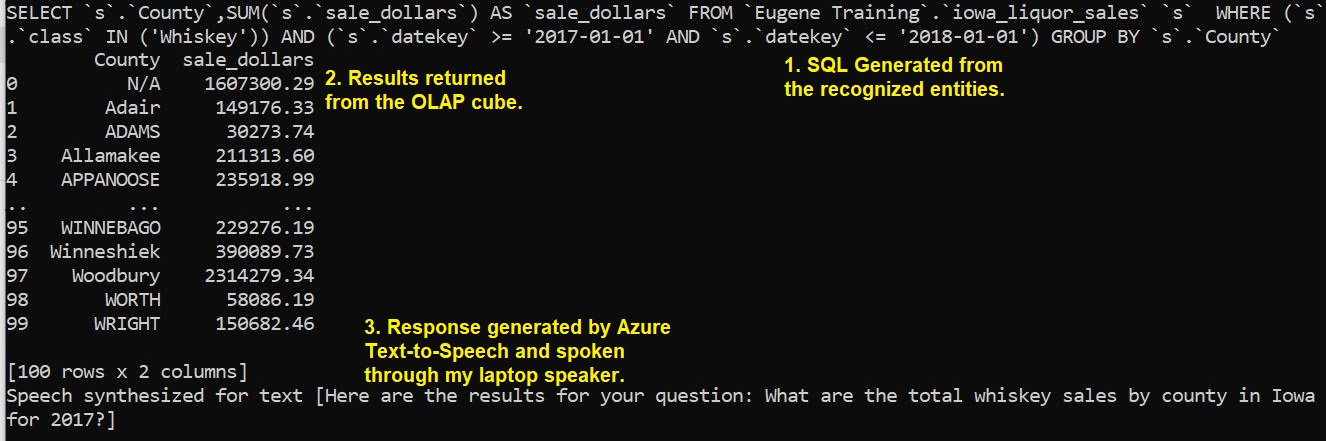
Figure 19 – Results of our query.
The code for constructing the SQL shown above is relatively simple after the heavy lifting of parsing out intents and entities from flexibly-worded questions by the Azure Language model is performed.
Let’s Rephrase That
The utterances I mentioned earlier (Figure 6) are rough samples of the structure of the spoken slice and dice query. The Language Service model can make out what you’re saying, even if it’s not in those exact words. To the point of the loosening of query syntax rigidity, the results are the same with a completely different phrasing of the same question:
- Original: What are the total whiskey sales by county in Iowa for 2017?
- New: In 2017 for Iowa by County, what are my sales for whiskey?
Figure 20 below, shows the same results using the rephrased query.
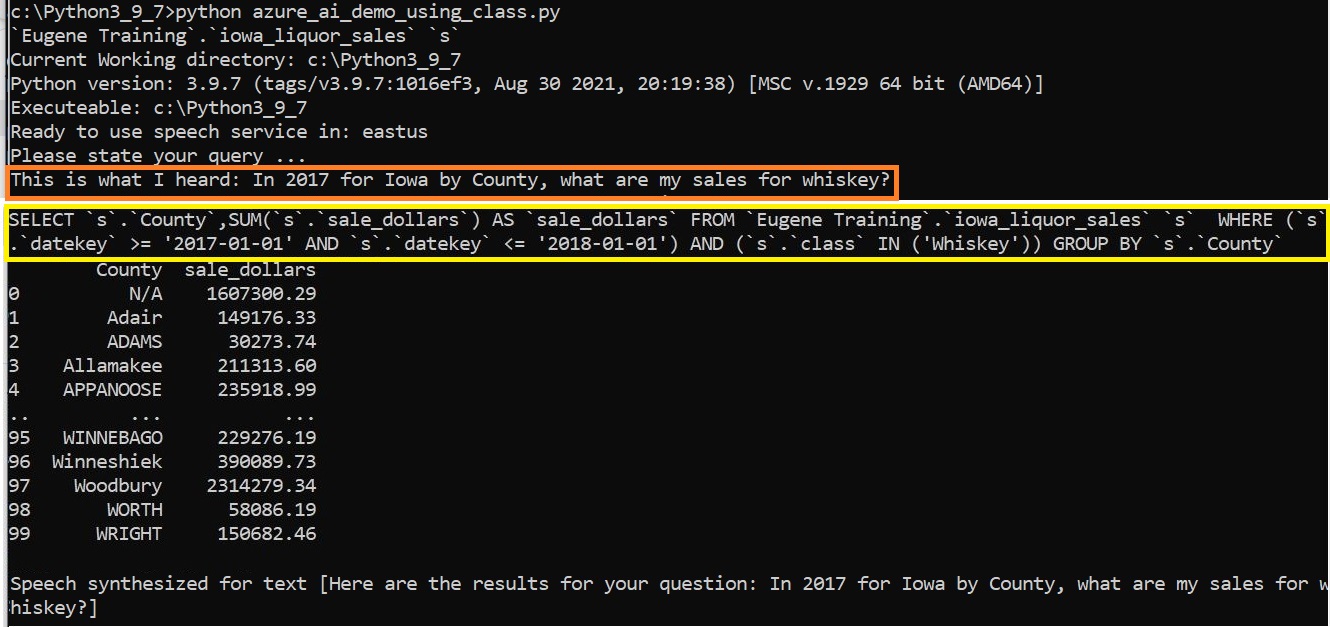
Figure 20 – Results from the rephrased query.
Comparing the two SQLs (Figure 19 and Figure 20), except for the order of the WHERE clause terms, they are exactly the same. This is a prime example of loosening the interface between the human and computer communication. In fact, utilizing Azure Speech Translator service, it’s even possible to ask the same question in a different spoken language.