
Processing data models with complex schemas is very time-consuming and requires a great deal of effort, especially if the dataset is large and wide. Imagine if users could build their first data model in just a few minutes!
To help them get started quickly with minimum bootstrapping work, Kyvos has introduced a new feature called quick data modeling. This feature allows users to connect to their data source and process a data model quickly, even if they are not a technical expert.
What is Quick Data Modeling
Typically, to start building your OLAP model you need to perform the following steps:
- Connect to the data
- Choose business data required for analysis
- Define relationships between datasets
- Design and process the data model
- And finally, create visualizations
This looks like a lot of steps!
Quick data modeling combines the first four steps into a single workflow. A wizard-based interface allows users to select their connection and data to register. Then, Kyvos automatically validates the data and creates relationships and cube design, thereby eliminating the effort and time needed to design the data model.
It’s More Than Just a Guided Modeling
There are several tools in the market today that offer guided data modeling. But Kyvos’ quick data modeling is not just a guided tour – it is an intelligent workflow-based system that creates a smart aggregation based on the data. And that too, very quickly!
Though this feature is extremely helpful for new users, it is equally beneficial for those who are experts in the domain but want to speed up their work without losing the flexibility to make changes based on their prior knowledge. The system uses its ML-based smart recommendation engine to provide intelligent suggestions at every step through the process. Users can review and make changes wherever needed.
Benefits of Quick Data Modeling
Here are some of the key benefits of Quick Data Modeling over the traditional step by step modeling:
- Speed
The end-to-end pipeline from connecting to a large number of data sources to coming up with an intelligent data model could just take a couple of minutes, instead of the hours needed, if performed manually. - Simplicity
An intuitive user interface takes the user through all the steps and does all the bootstrapping work in the background, right from identifying the facts and measures to coming up with a recommended data model. This makes it easy to work with complex data models, even if the user does not have technical expertise. - Intelligence
The system auto-detects relationships, auto-validates all objects in a single go and comes up with a model based on the data profile. Once the intelligent design is done, users can further fine-tune it based on their SLAs.
Wizard-based intuitive interface
To use the quick data modeling feature, users need to perform the following steps:
-
On the Kyvos home page, click quick data modeling and provide a name for the analysis. Kyvos automatically creates all the folders, relationships and the data model with this name.
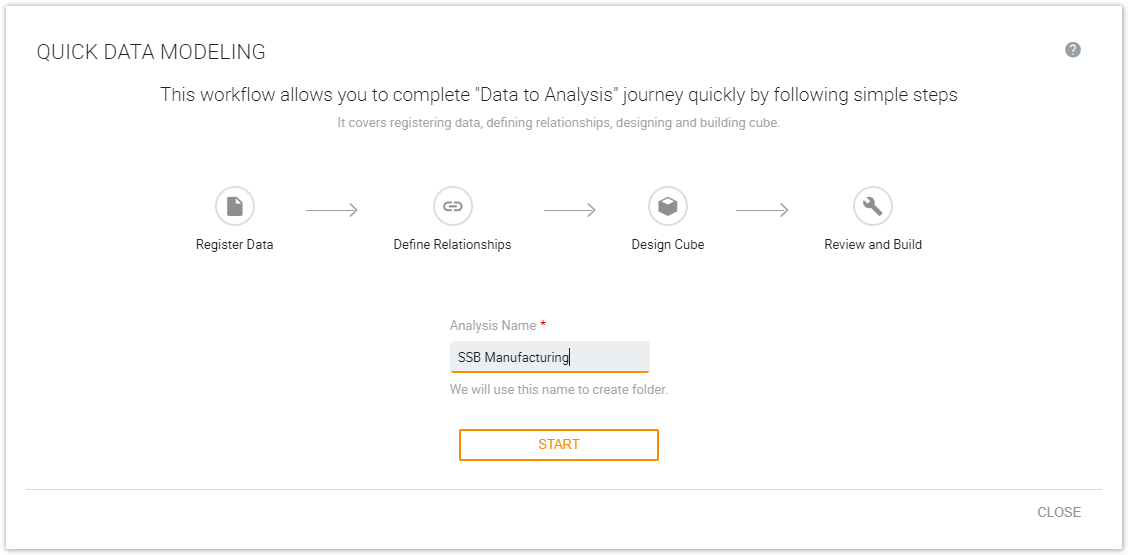
-
Create a connection to the data source on the ‘Register Data’ tab. Users can also connect to multiple data sources here. Once the connection is set, they can add the files or tables on which they want to process the data model. At this step, the user can mark the tables as dimensions or facts, filter data and columns from the tables, define column properties and perform other advanced operations.
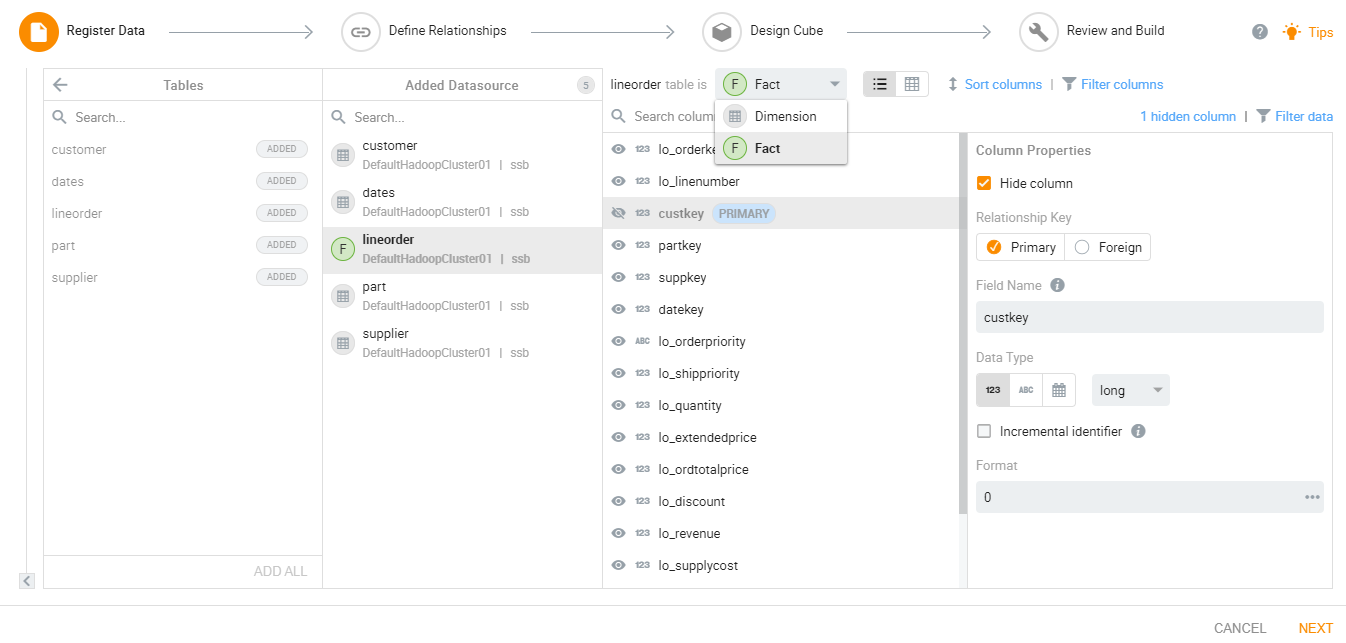
The system validates the files and tables and displays errors if the data is invalid.
-
Once the files are registered, the user will see a set of relationships automatically created by the system under the ‘Define Relationships’ tab. They can also define custom relationships manually here.
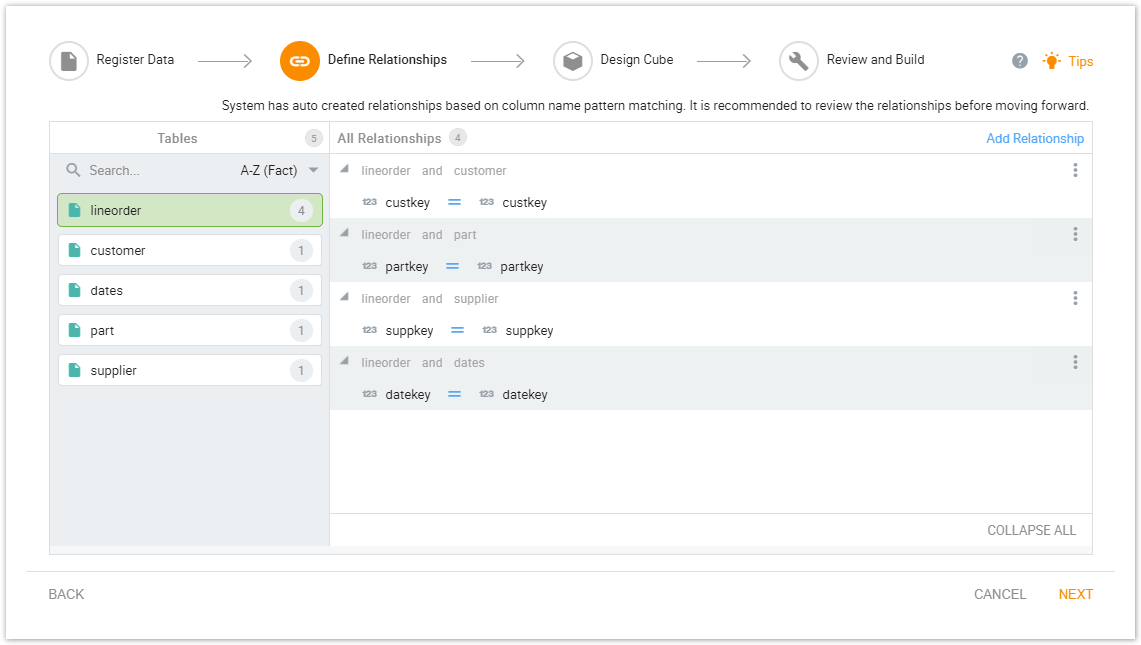
-
Next, the system validates relationships and creates a data model design that is displayed under the ‘Design Cube’ tab. The users can modify the design to add dimensions, measures or define properties and more.
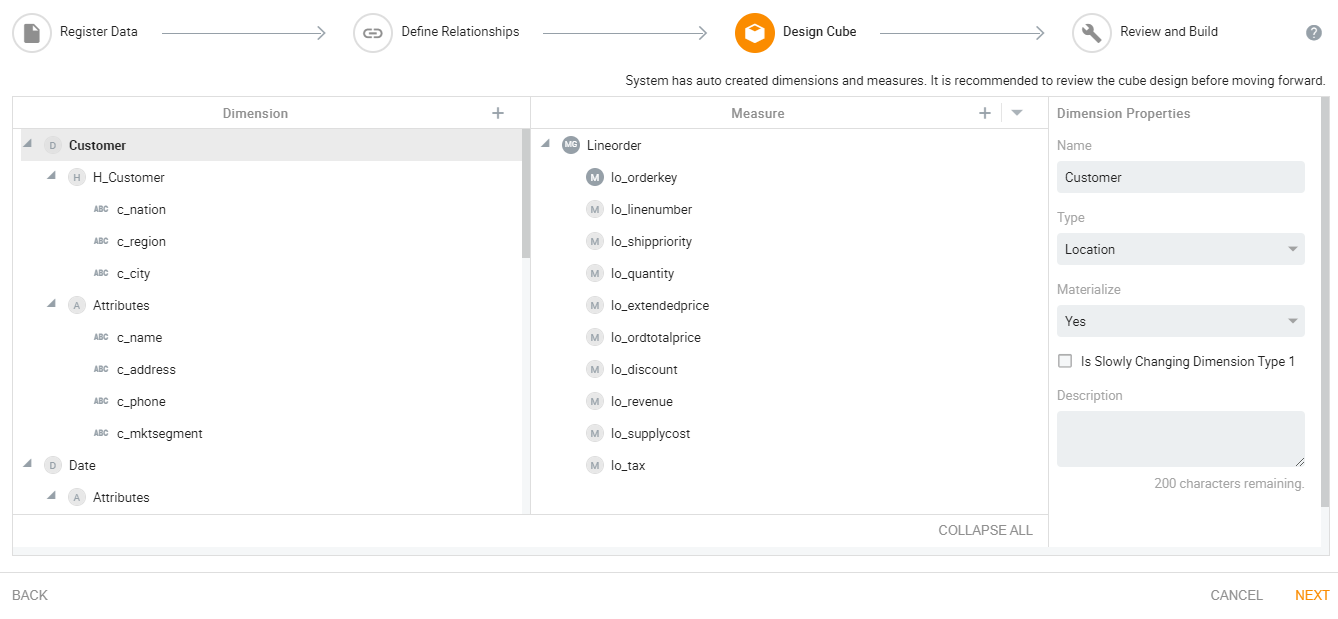
-
Finally, the user can execute a test build from the ‘Review and Build’ tab. Here, they can specify the number of records or partitions to be processed in the test build. They can also minimize aggregations if needed.
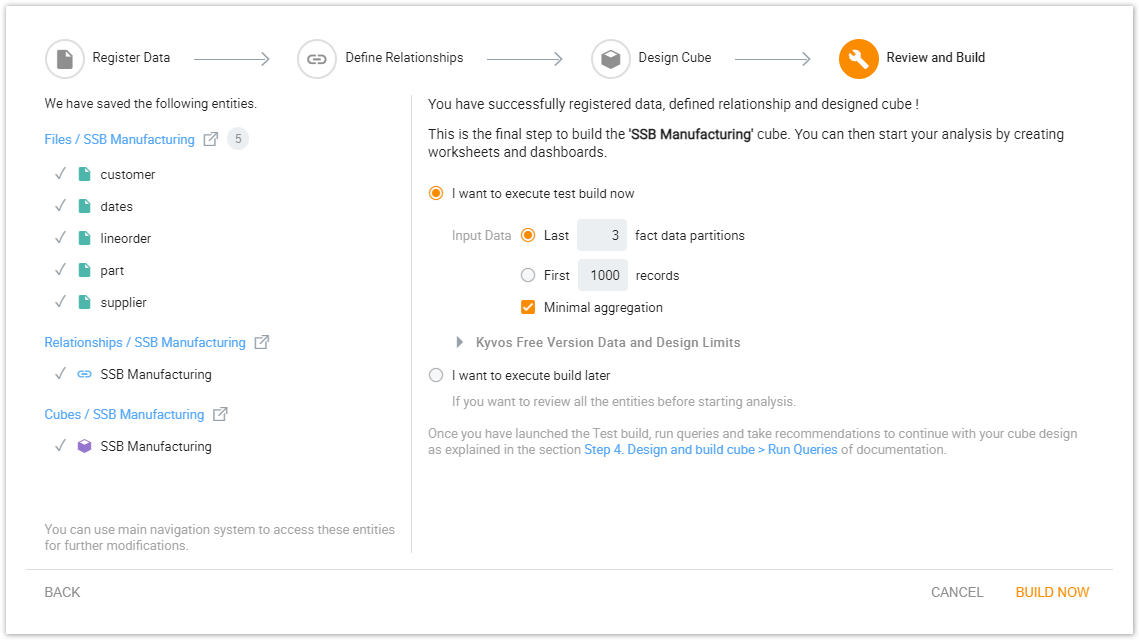
- After the successful completion of the test build, the user can create visualizations and start running queries to generate recommendations to further optimize the design.
How to use Quick Data Modeling
Real-world data is often quite complex and so are the business requirements. Hence, optimization is the key to processing a successful data model that maintains a balance between the number of resources needed, the SLA requirements and the demands of the business users.
Designing an optimized data model needs both intelligence as well as experimentation. The following steps will help leverage system intelligence and user feedback to build a robust data model.
- Initial design
Build the first data model using quick data modeling and run a test build. - Training your model
Put it in the hands of business users and allow them to fire queries. - Learning mode
Our ML-powered smart recommendation engine starts capturing the queries and profiles the data to provide recommendations on optimization options. - Optimization
Apply the recommendations and update the aggregates. The iterative cycle continues, and the system keeps on learning and updating until all the requirements are met.
In the end, the user gets an optimized data model that can deliver on the SLAs, while ensuring optimal resource utilizations and keeping a check on the costs.
Want to learn more about quick data modeling for analysis and other advanced features? request a demo now.